

Introduction
Hey there! Have you ever wondered how artificial intelligence (AI) perceives you? It might seem like a futuristic concept straight out of a sci-fi movie, but the truth is, AI technologies are already making significant strides in understanding the world around them, including us humans. So a question such as “how AI sees me?” is not so far-fetched.
In this article, we’re going to delve into the fascinating realm of AI’s visual perception, particularly focusing on the way neural networks, specifically Convolutional Neural Networks (CNNs), see and interpret images of human faces. So, buckle up as we embark on a journey to demystify AI’s perspective!
Types of AI that Could Perceive Humans
AI, in its various forms, can perceive humans through different modalities, such as speech recognition, text analysis, and image processing. However, for this discussion, let’s zoom in on computer vision, a subset of AI that enables machines to interpret and understand visual information like images and videos.
Among the numerous computer vision models, one stands out as foundational when it comes to recognizing and analyzing images: Convolutional Neural Networks. That is because it consists of convolutional filters, which are special types of neurons that learn spacial 2D knowledge. That enables them to be performant in the vision domain, where proximity of pixels matters.
How AI Sees Me? – Through the Eyes of Convolutional Neural Networks
Imagine a CNN as a complex visual cortex that takes an image of a person’s face and breaks it down into intricate details, much like our brain processes what we see. CNNs consist of layers of interconnected neurons, and each neuron corresponds to a specific feature in an image.
When you feed an image into a CNN, it undergoes a series of convolutions, where convolutional filters highlight certain patterns within the image. This is called neuron activation. The more resemblance between a learned feature and a part of the image that activates it, the more a neuron gets activated. You can think of this activation as signal strength.

Let’s say you’re showing the CNN an image of a smiling female with all her facial features. The very basic features, such as lines, dots, and parts of shapes, are learned in the first layers of the CNN. In the middle layers composite features start to form, such as circles, squares, triangles, simple patterns. And the deeper you go in the neural network, the more complex the knowledge becomes.
In the very deep layers of these networks, if we have as example a face recognition CNN, we see whole noses, eyes, and even whole faces being learned.
This hierrarchical nature of CNNs and neural networks in general is the core of their effectiveness in tackling all sorts of problems. It enables them to “see” you.
In that sense, you can think of a complex task as a function that needs to be approximated. And in order for this to happen one needs a powerful, even universal, function approximator. That is where interconnected layered neural networks come in handy. Once you tinker their neurons and connections through training, you (usually) get an approximation of a given function, which represents the task at hand.
Learning Features – The Magic Behind CNNs
So, how do CNNs learn these features to “see us”? It’s a bit like teaching a child to recognize different animals. At first, you show them simple pictures like circles and squares, helping them understand basic shapes. As you introduce more pictures, the child begins to differentiate between animals better and better. Similarly, CNNs are trained on a massive dataset of labeled images. The network adjusts the weights of its neurons during training to minimize the difference between its predictions and the true labels.
For example, the network might learn that certain neuron activations correspond to the presence of a curved line, which is common in lips. Over time, through multiple iterations of training, the CNN refines its understanding, recognizing more intricate features and eventually piecing them together to identify complete objects or scenes.
Example – Deciphering the Human Face
Consider the scenario where you show a CNN an image of a smiling woman. The initial layers detect the edges of her face, while subsequent layers activate when the network identifies the curves of her lips, the symmetry of her eyes, and even the unique pattern of her smile lines. Each layer’s activations contribute to the network’s final decision, classifying the image as a person with specific attributes.
Consider the scenario where you show a CNN an image of a smiling woman. The initial layers detect the edges of her face, while subsequent layers activate when the network identifies the curves of her lips, the symmetry of her eyes, and even the unique pattern of her smile lines.
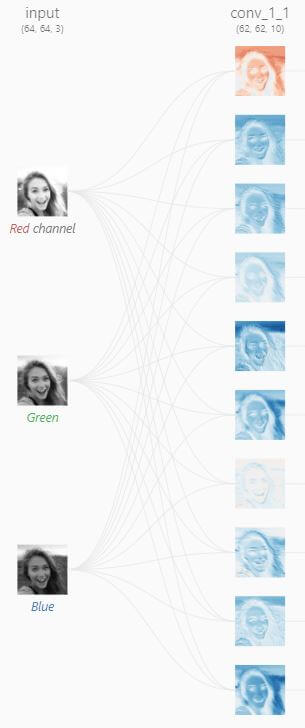

Initial Layers
In these early stages, the CNN acts like a keen observer focusing on the broader strokes of the image. Just as an artist sketches the rough outlines before adding intricate details, the initial layers of the network detect fundamental elements. These layers capture the fundamental edges and shapes that form the basis of the woman’s face and her smile.
As you can see on the right, the first image shows the feature activations of an input picture of a woman’s face. The red to blue spectre of the activations shows the degree of activation of a given convolutional filter.
Take the first filter (on top). The red indicates that it is weakly activated by most of the image, except what looks to be the hair part of the woman’s face. This could mean that it is activated by strand-looking lines.
On the other hand, the 5th filter from top to bottom seems to be activated by the sky part of the image. So its feature map might resemble a more uniform feature, maybe even a solid fill, which the sky part is made of.
Deeper Layers
As the image moves through the network’s layers, its understanding becomes more refined, much like an artist adding fine details to a painting. Subsequent layers activate in response to specific features: the gentle curves of her lips, the symmetry in the placement of her eyes, and the subtle lines that reveal her joyful smile. These layers work in harmony, each contributing to the AI’s comprehensive perception of the image.
As seen on the rightmost picture, the feature maps are more complex. That is evident by the more specific activations.
For example, take the third column, second row activation. It seems to be activated mostly by the eyes, lips and ears of the face (because of the blue color). This indicates more complex features learned.
Computer Vision Applications in the Real World
Convolutional Neural Networks (CNNs) have sparked a revolution that’s touching our lives in ways we never thought possible. Think about how you unlock your smartphone with just a look – that’s CNNs at work, making tech feel like magic. They’re not just stopping there; these networks are the silent superheroes in our security systems. At airports and access points, they’re the digital bouncers, scanning faces and making sure only the right people get through.
But CNNs aren’t just about convenience and security; they’re changing the game in healthcare too. Picture this: they’re helping doctors spot diseases in medical images faster and more accurately. X-rays, MRIs, you name it – these networks are like Sherlock Holmes for doctors, uncovering clues that might have been missed. It’s like having an extra pair of incredibly sharp eyes right where they’re needed most.
From our gadgets to our safety and health, CNNs are rewriting the rules. They’re the real-world magic wands transforming how we live, and it’s happening right before our eyes.
Conclusion
And that’s how we wrap our discussion about how AI sees us. We’ve had quite an engaging one, too, haven’t we? Convolutional Neural Networks (CNNs) have quietly reshaped how we perceive the world around us.
Picture this: just as you notice the fine details that define a face, CNNs dive into images, layer by layer. They’re like digital detectives, uncovering each unique feature that makes us who we are. But remember, it’s not just about pixels – it’s a new way of understanding.
So, next time you glance at a photo, keep in mind that AI’s “vision” goes beyond what we see. It’s a process of learning, a window into a future where machines truly comprehend our reality. It’s an intriguing path ahead, where technology and insight merge to shape the world that’s unfolding before us.



Leave a Reply